Publications
2026
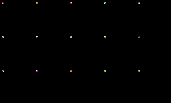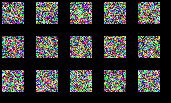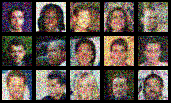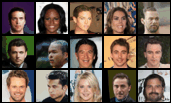
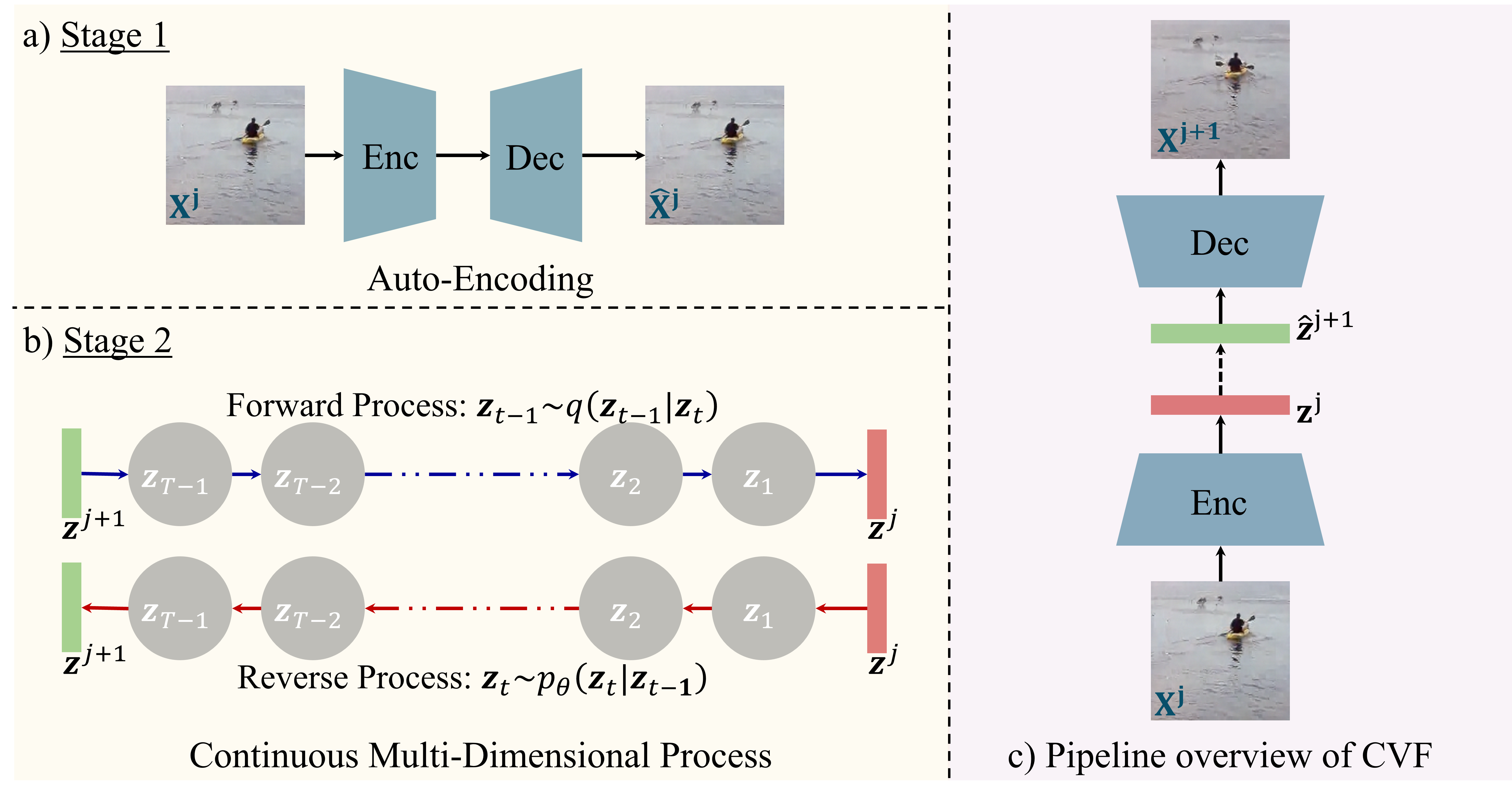
Scale Space Diffusion
CVPR 2026

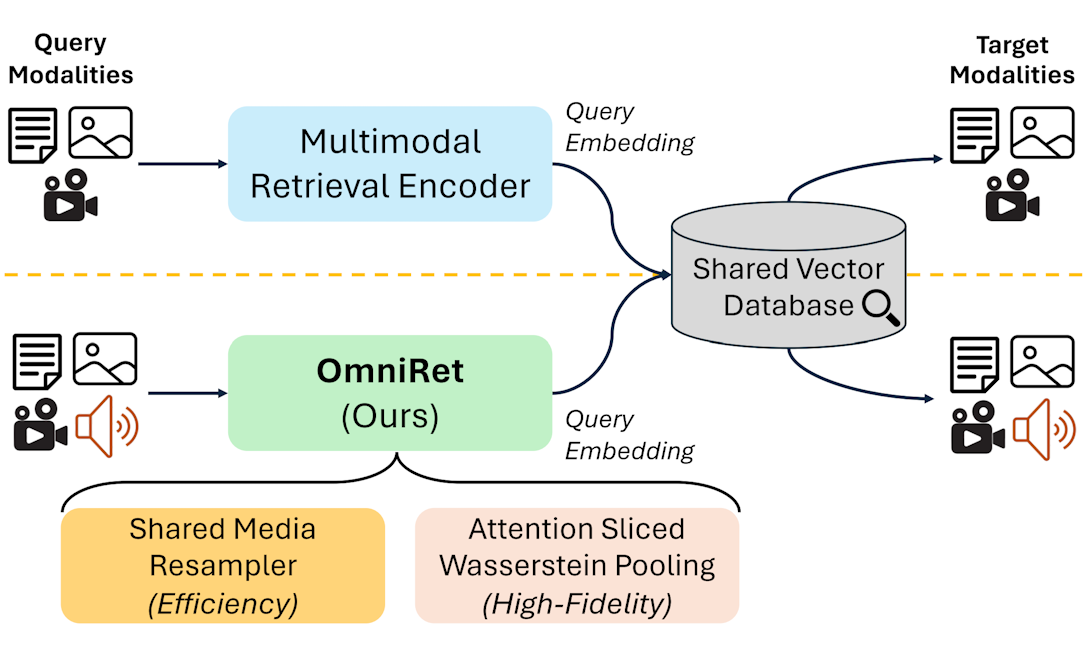
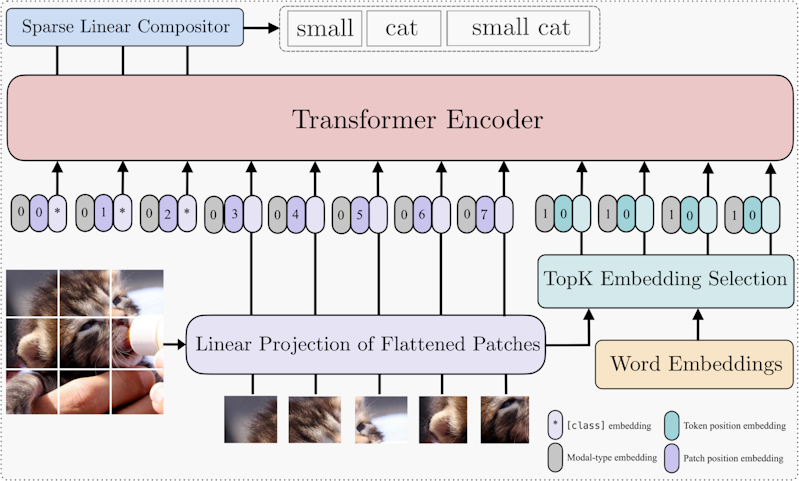
Efficient and High-Fidelity Omni Modality Retrieval
CVPR 2026
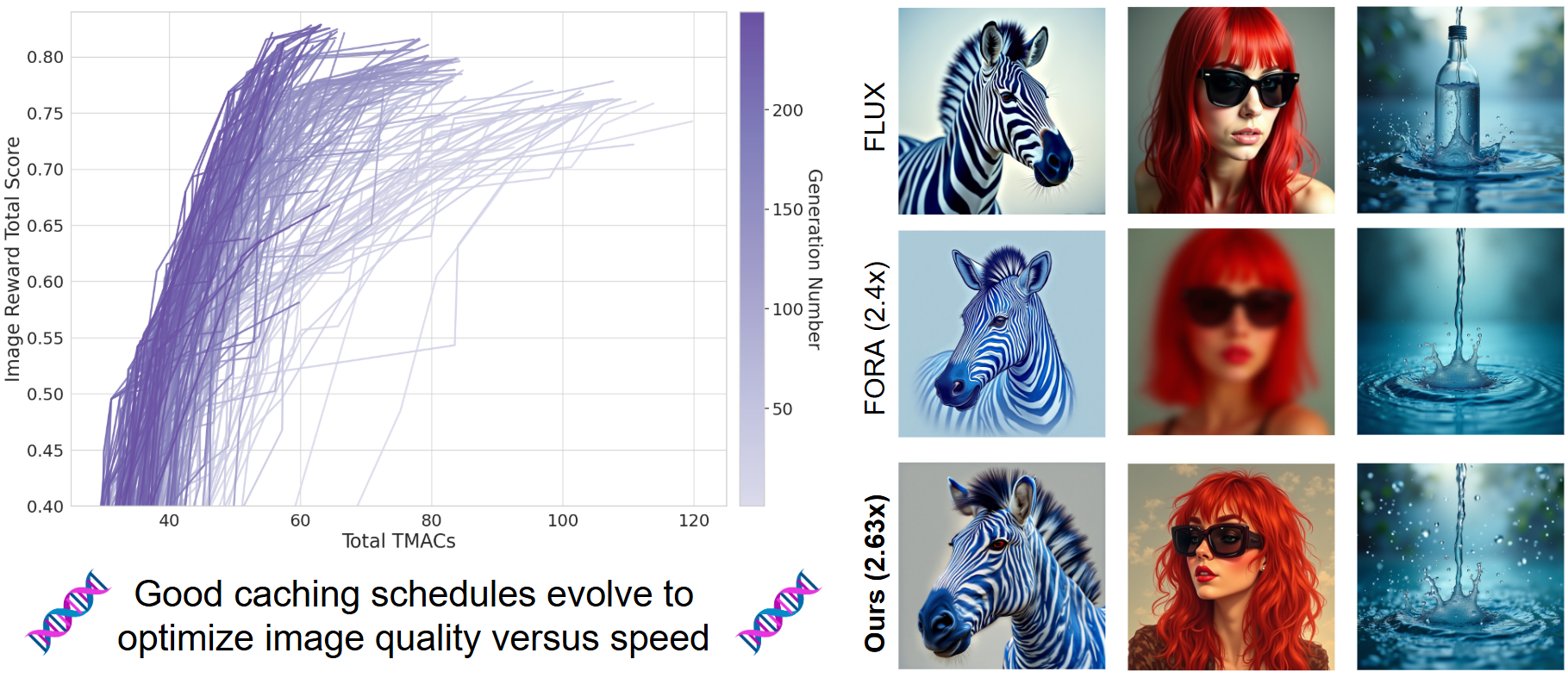
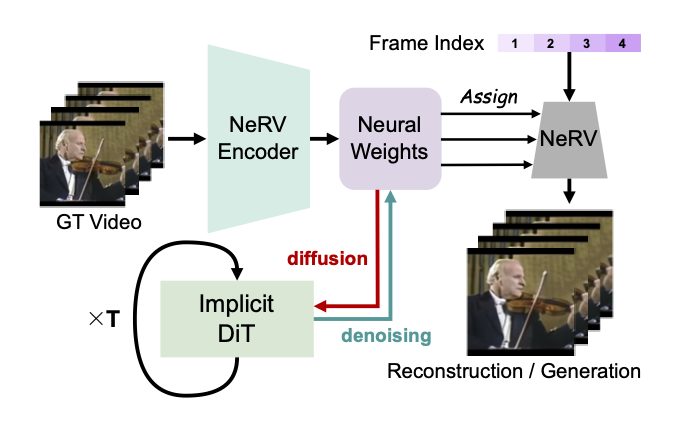
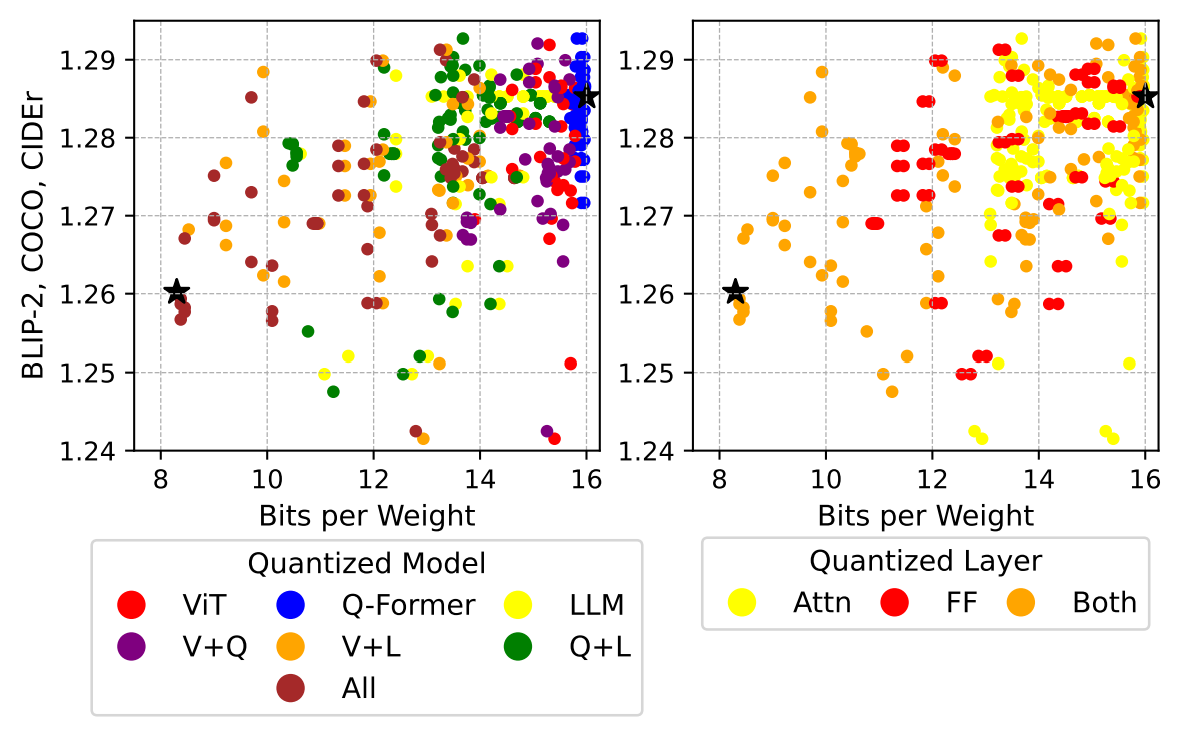

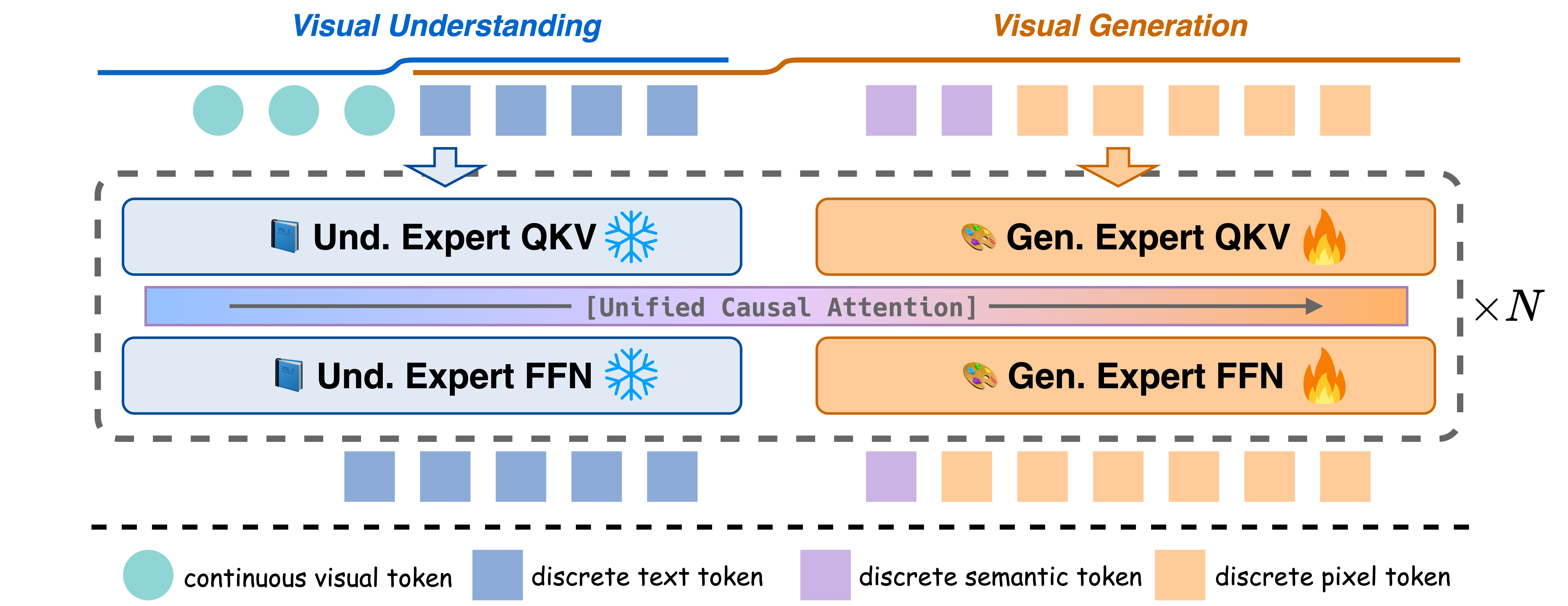
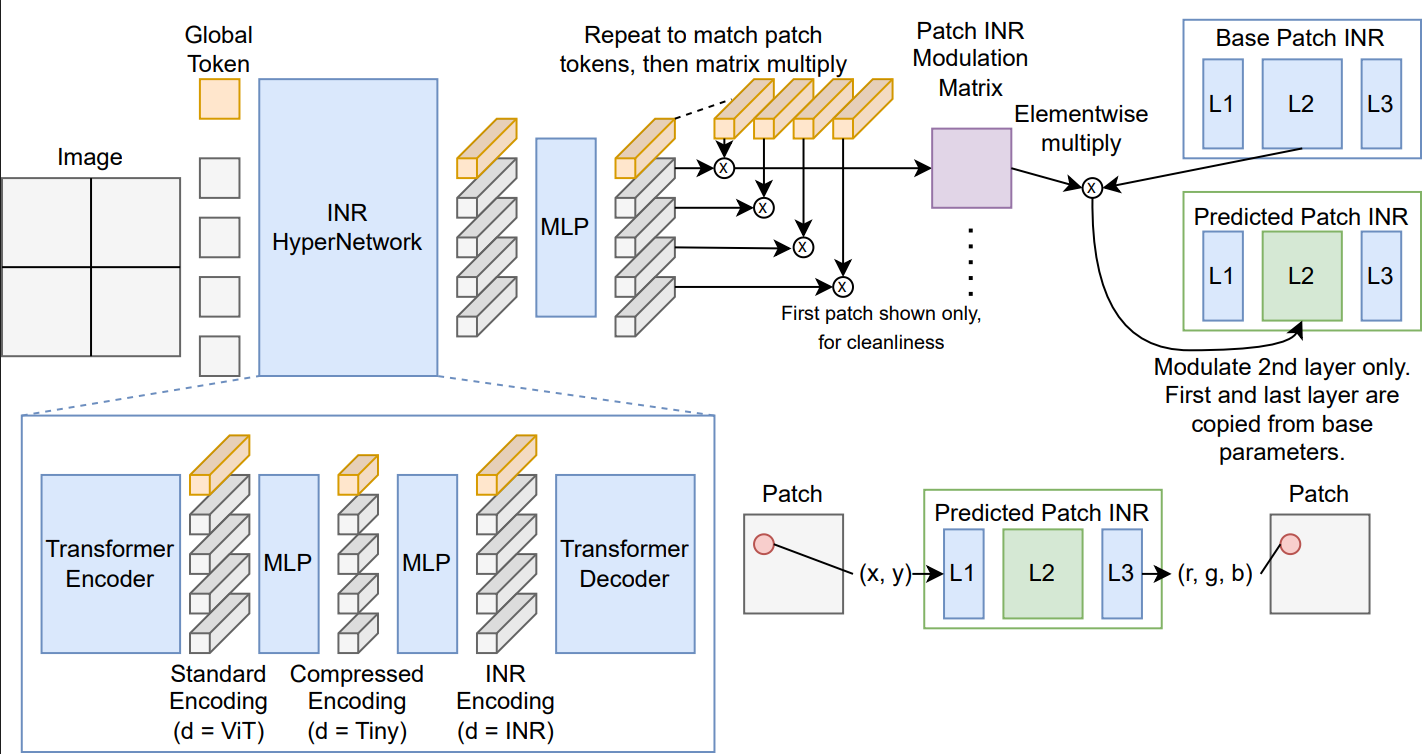
2025
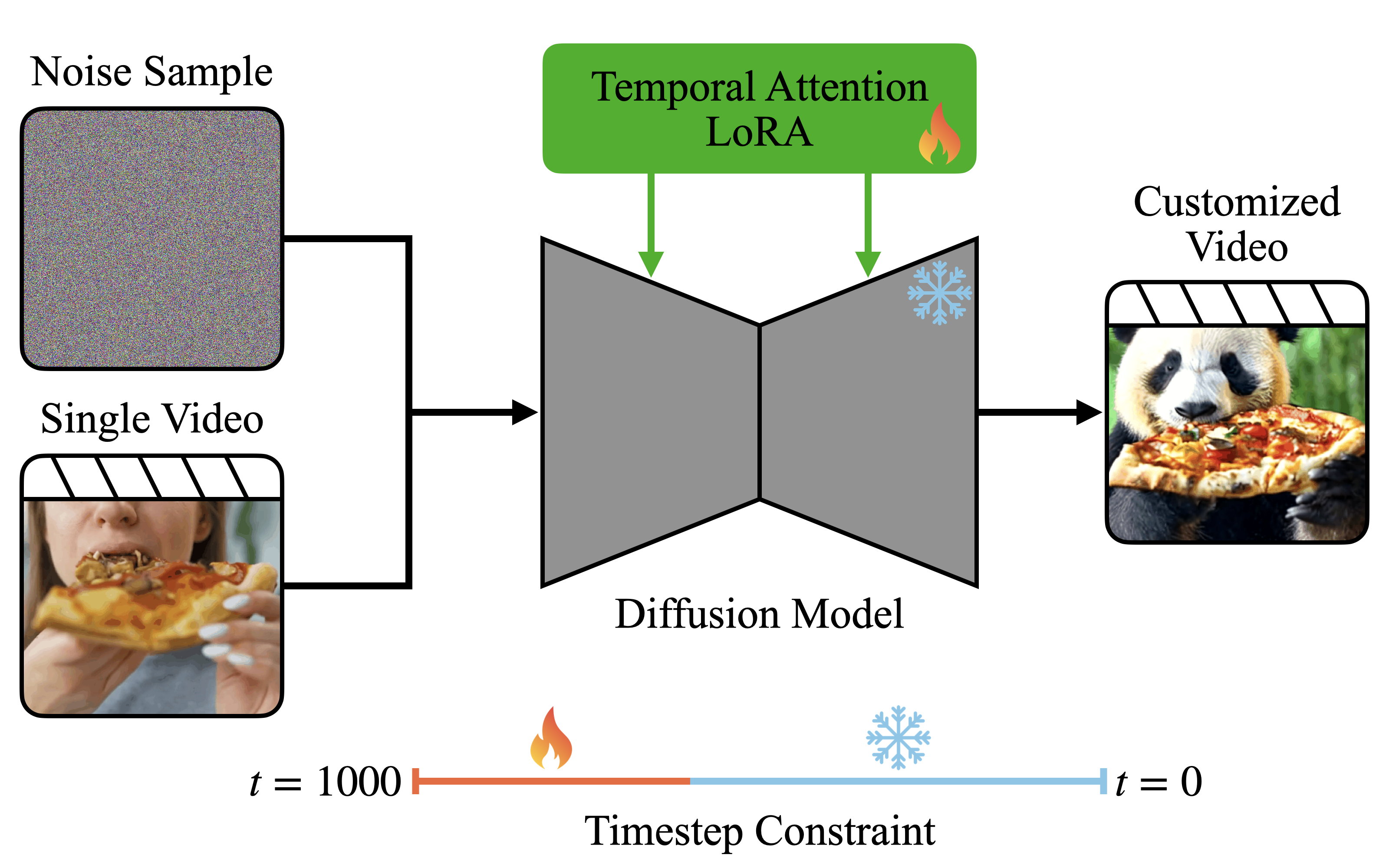

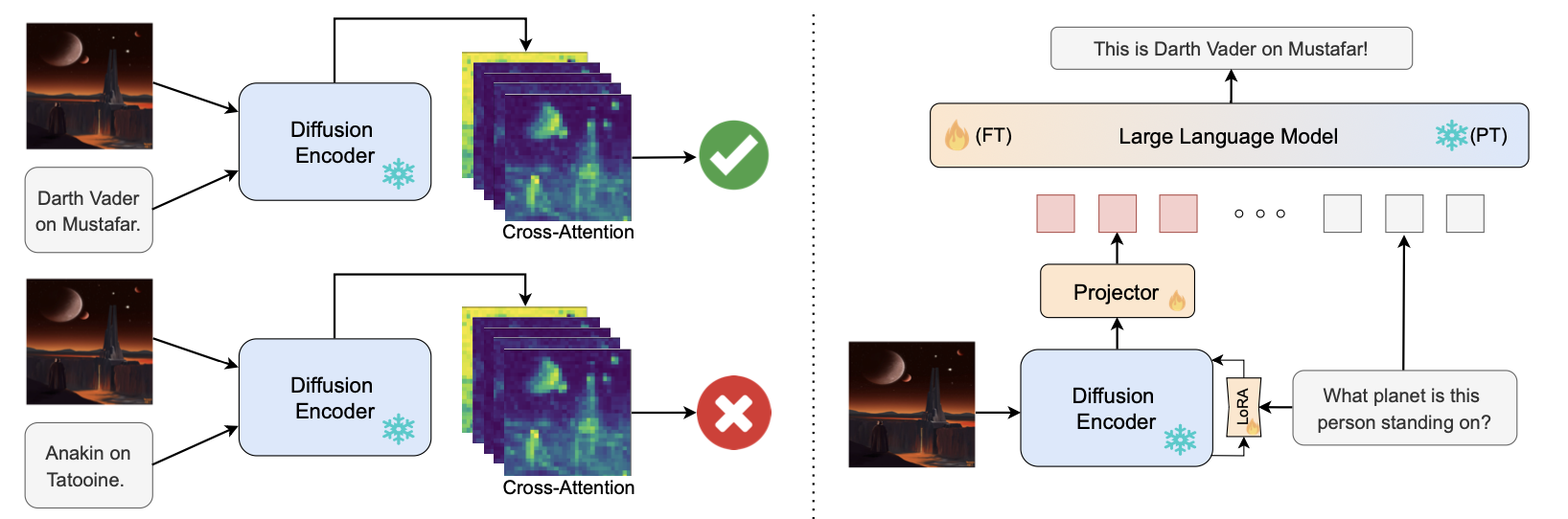

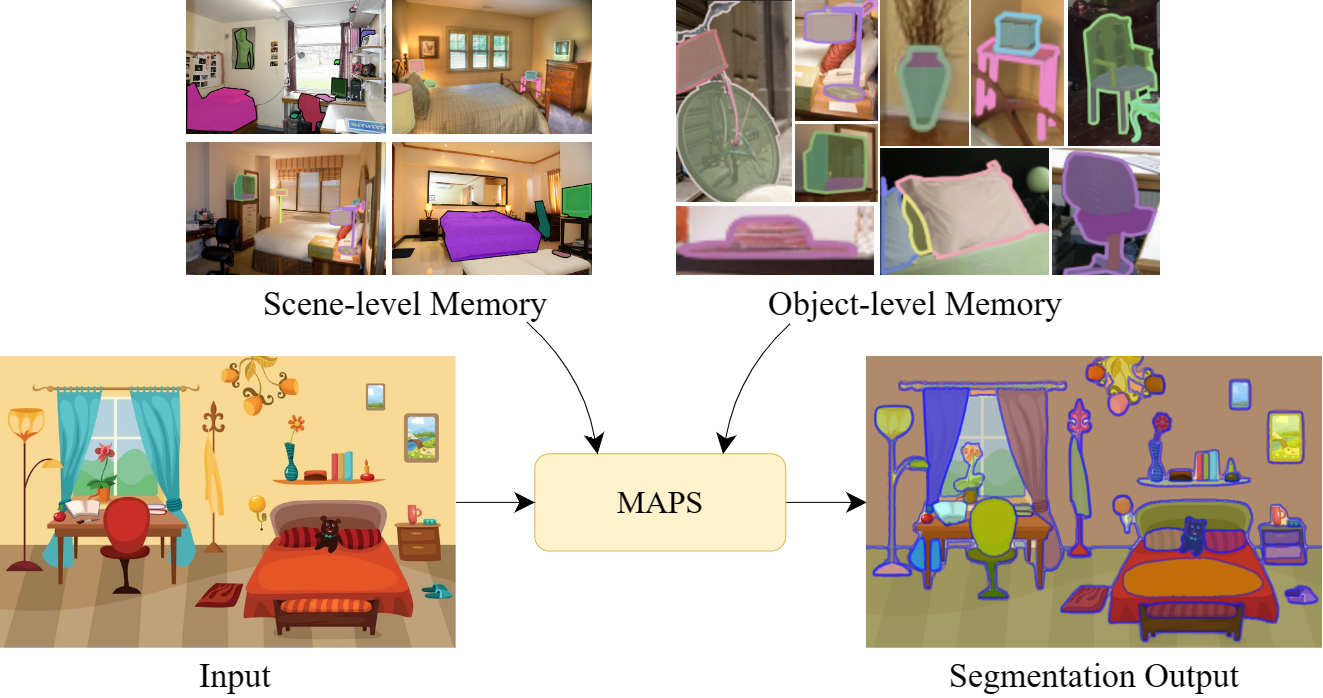

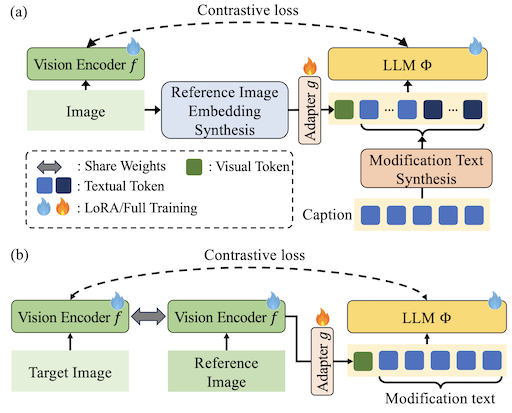
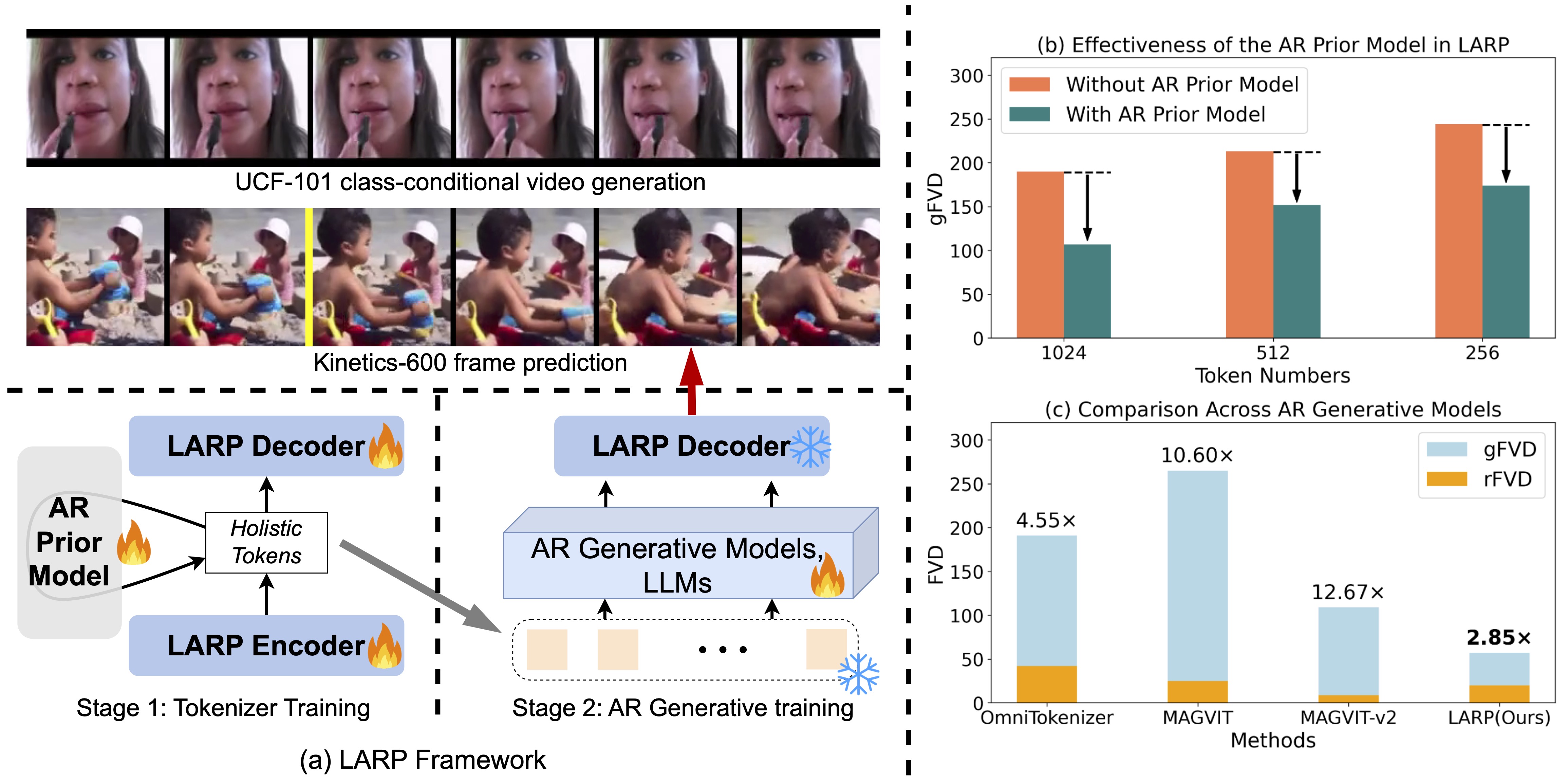

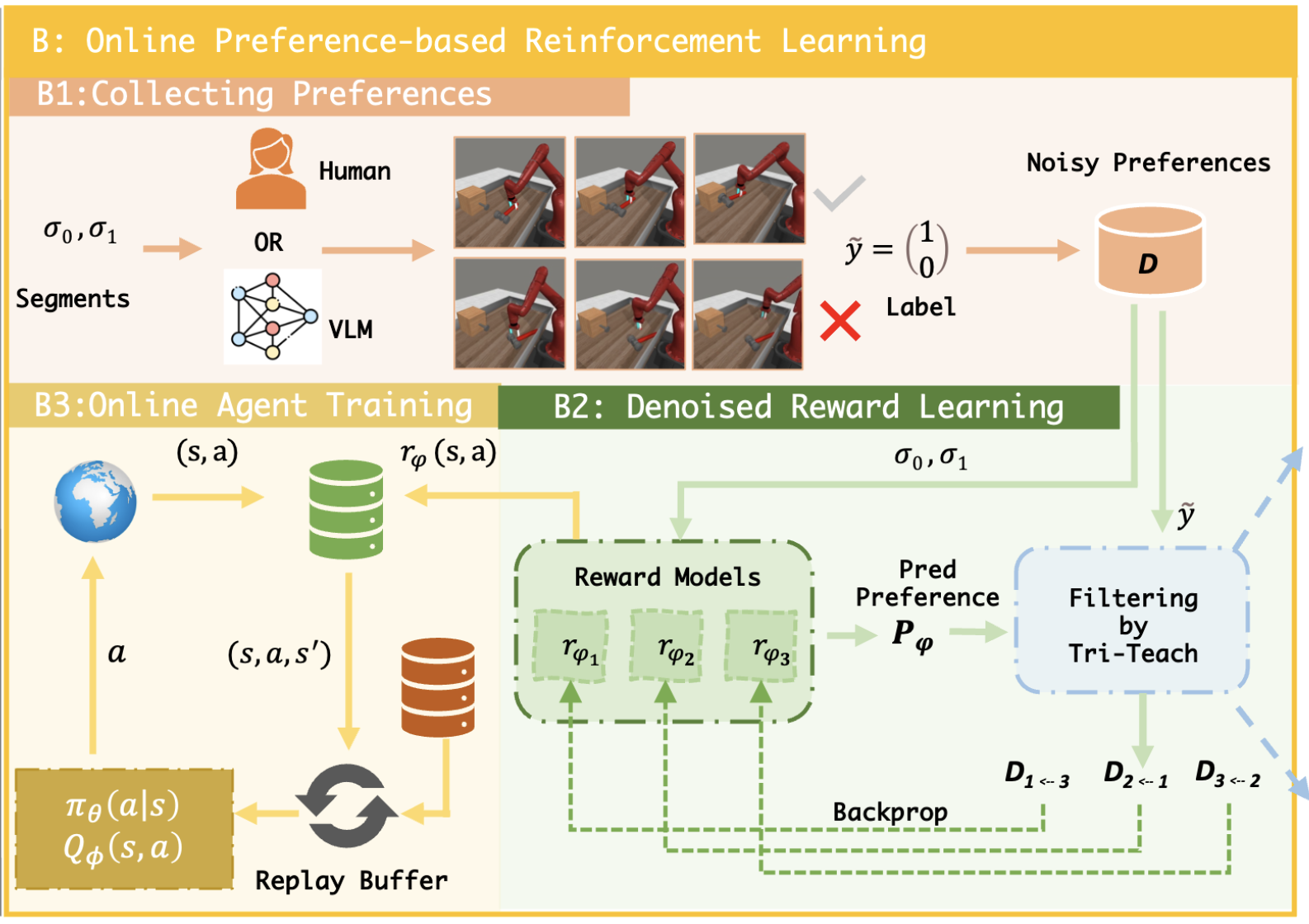

2024







Quantifying NBA Shot Quality: A Deep Network Approach
ACM MMSports 2024

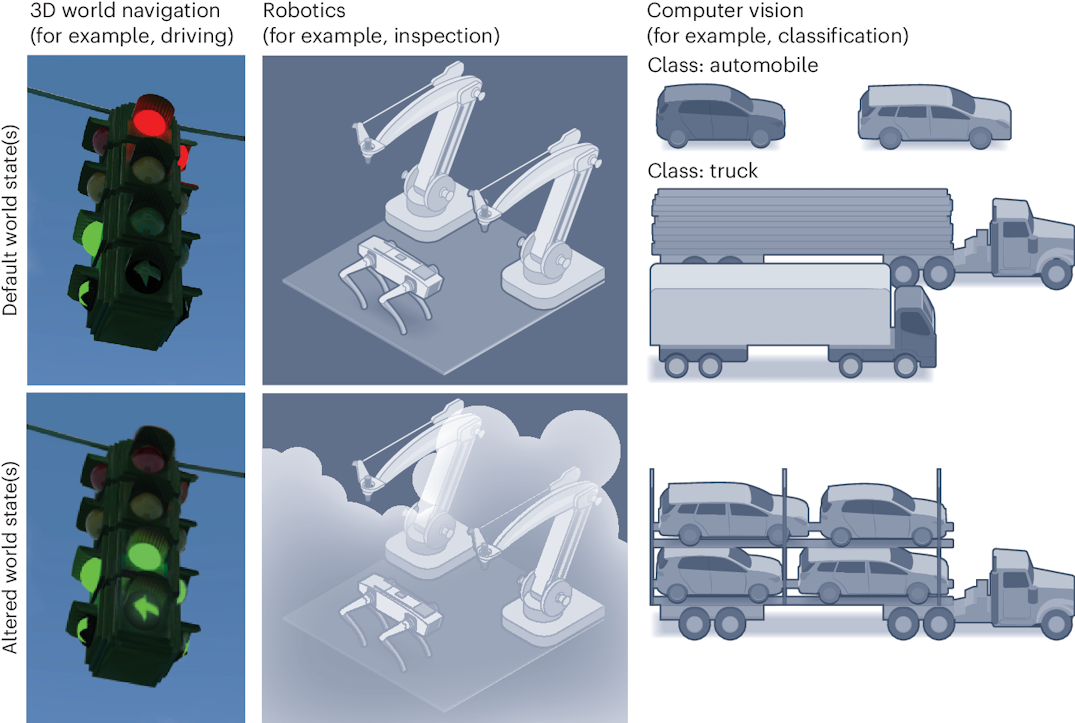
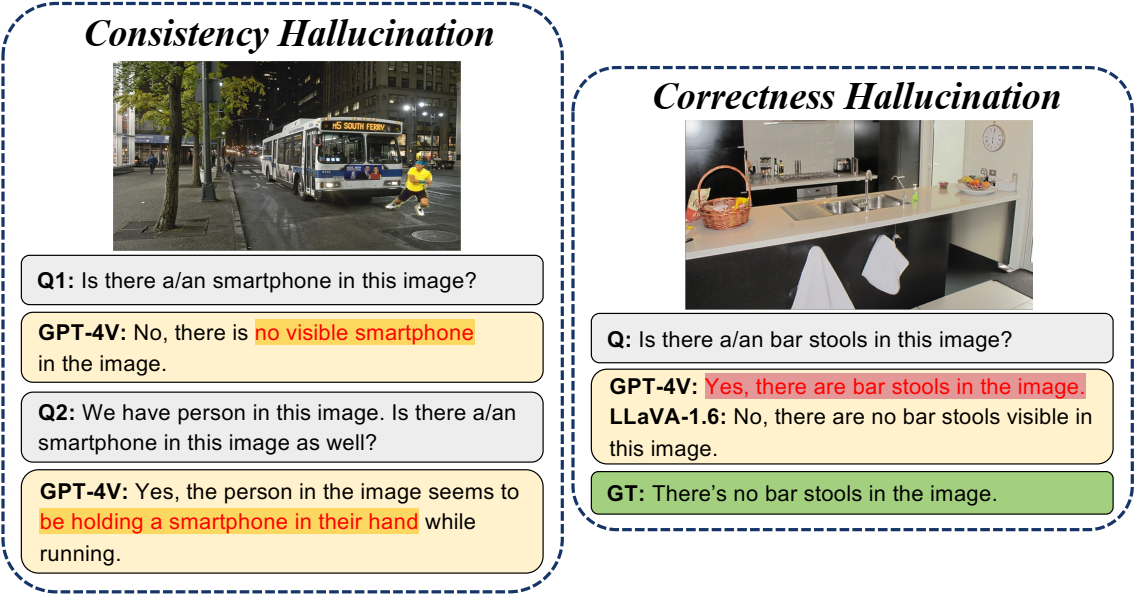
Challenges, Evaluation and Opportunities for Open-World Learning
Nature Machine Intelligence 2024
pdf /
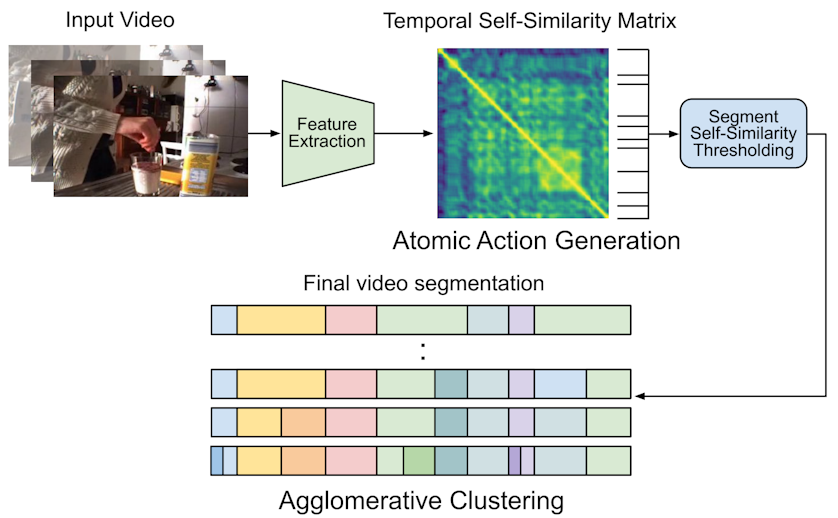
Agglomerative Clustering of Atomic Actions for Unsupervised Action Segmentation
LPVL Workshop, CVPR 2024



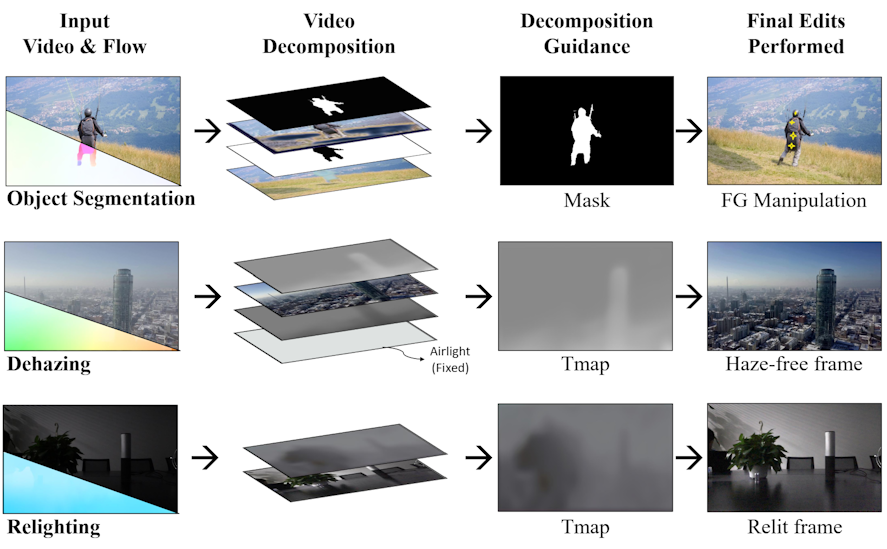



Leveraging Bitstream Metadata for Fast, Accurate, Generalized Compressed Video Quality Enhancement
WACV 2024
pdf /

2023



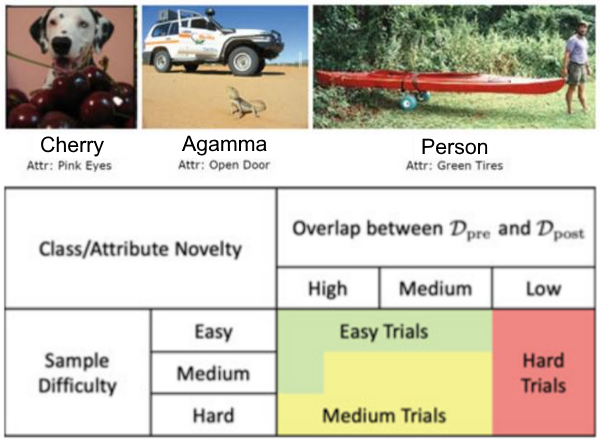
Novelty in Image Classification
Springer Book Chapter 2023
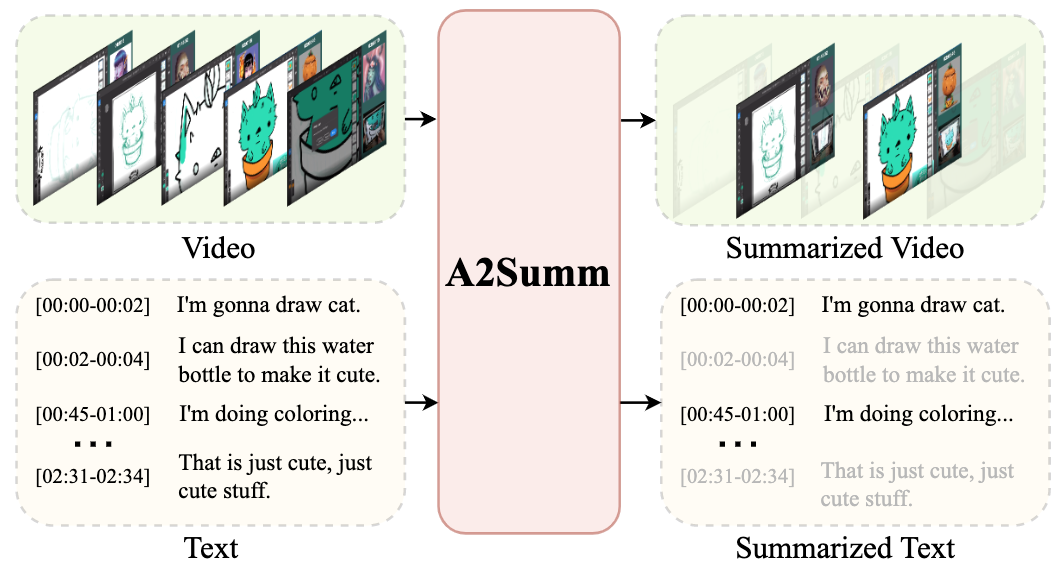


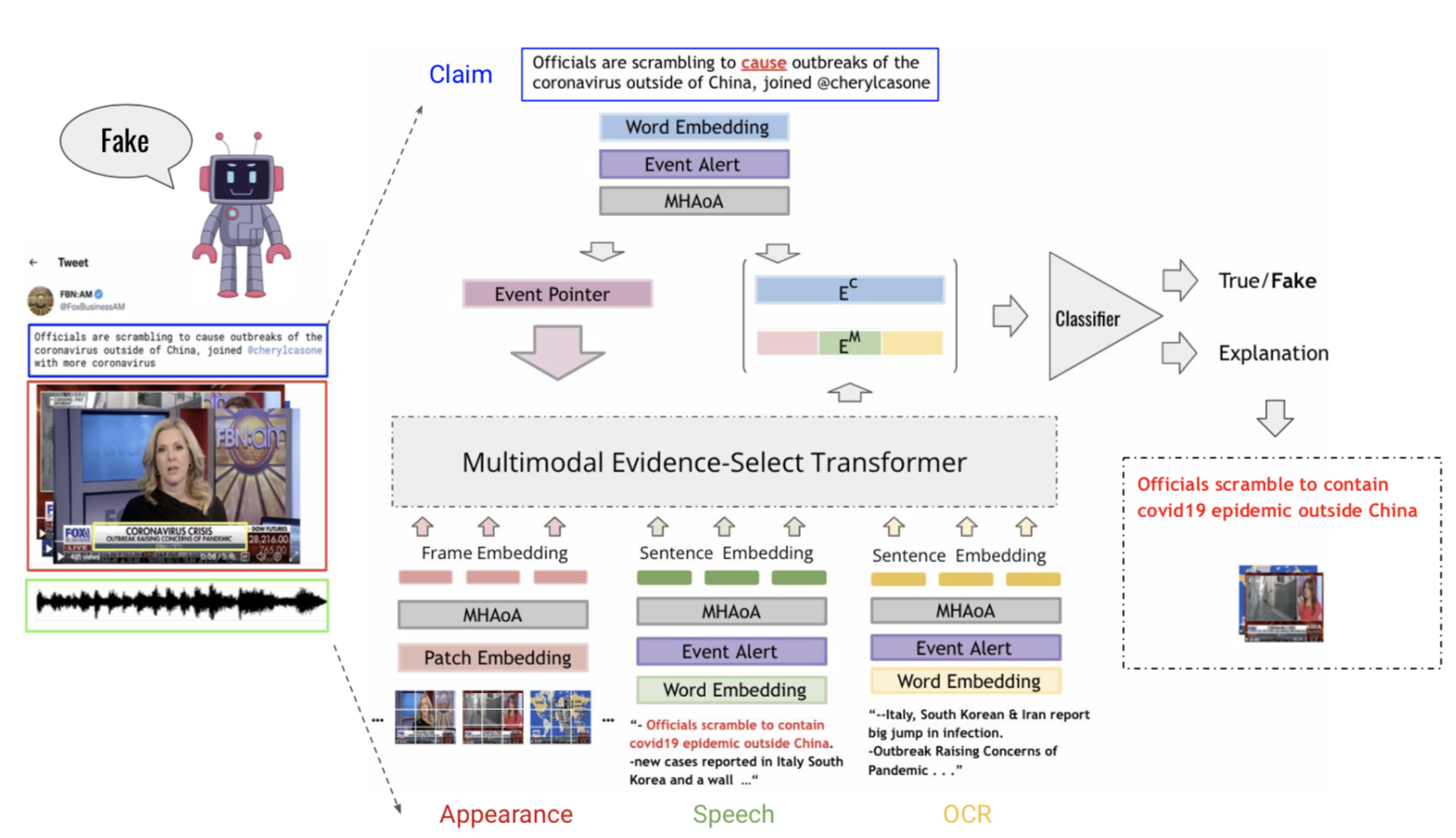
COVID-VTS: Fact Extraction and Verification on Short Video Platforms
EACL 2023
2022




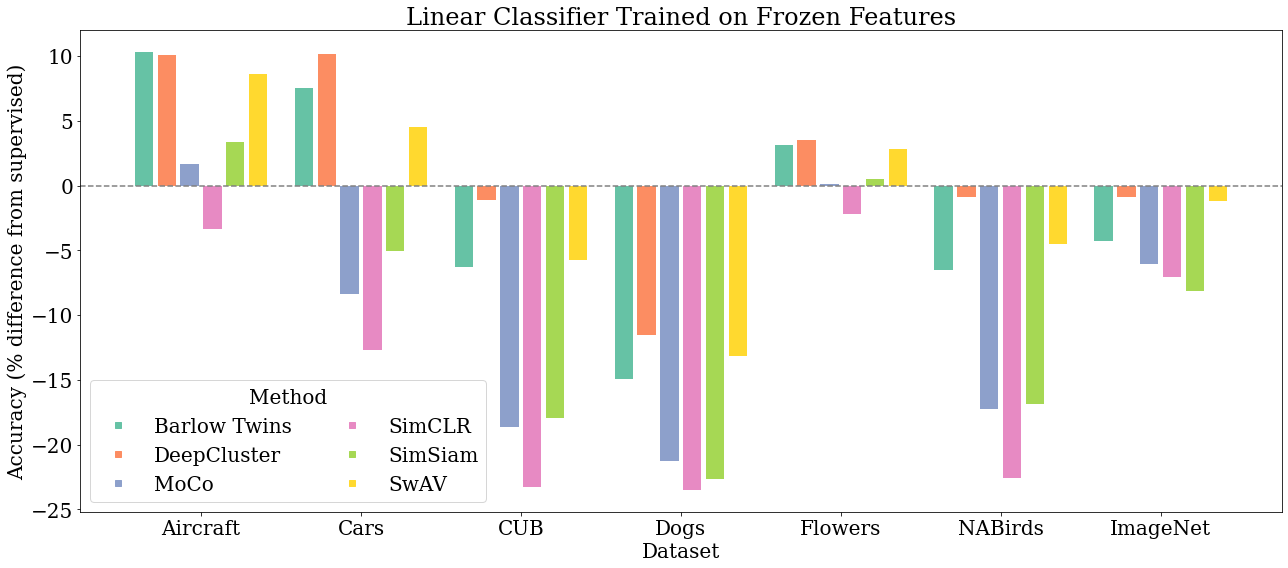




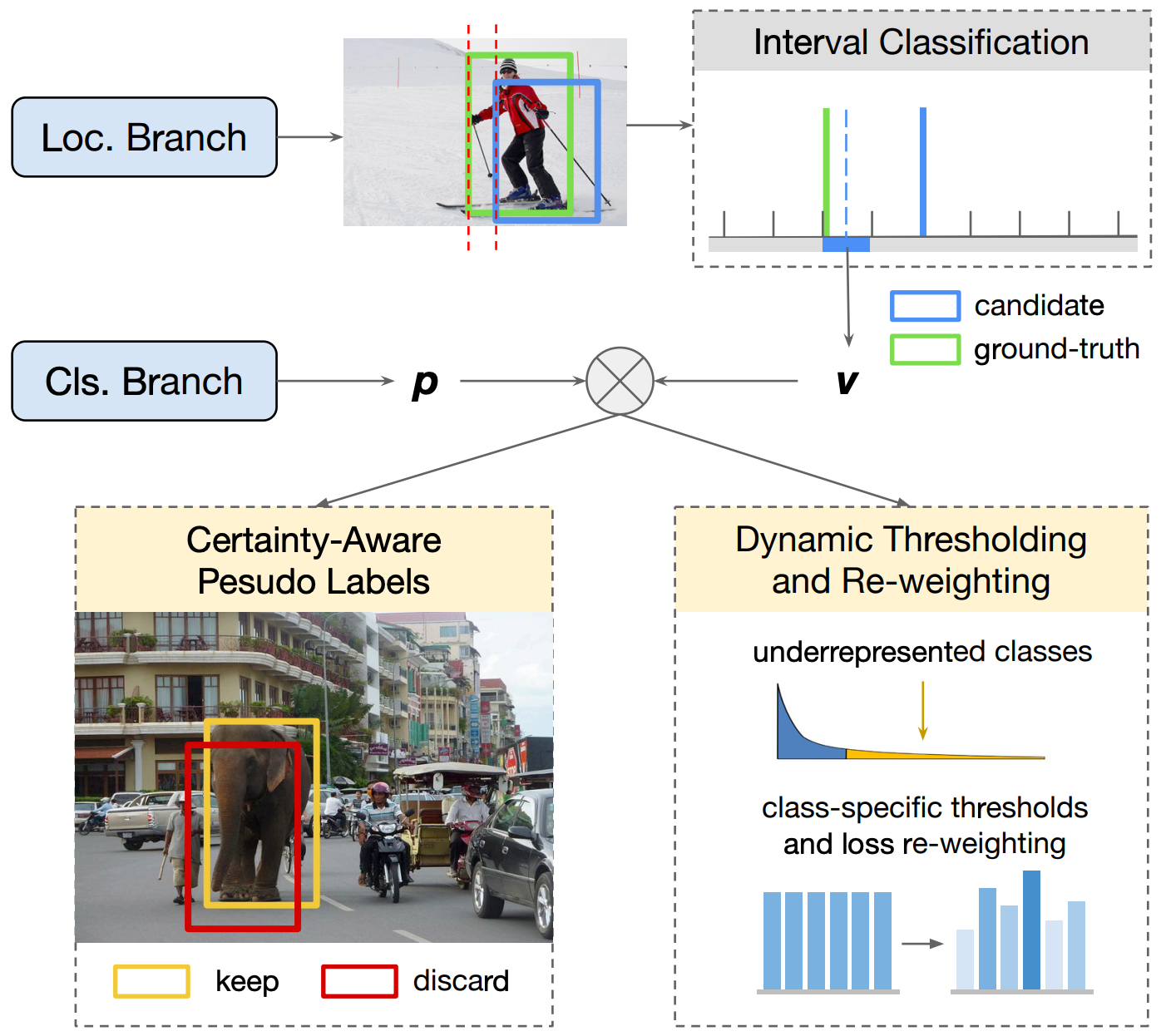
2021


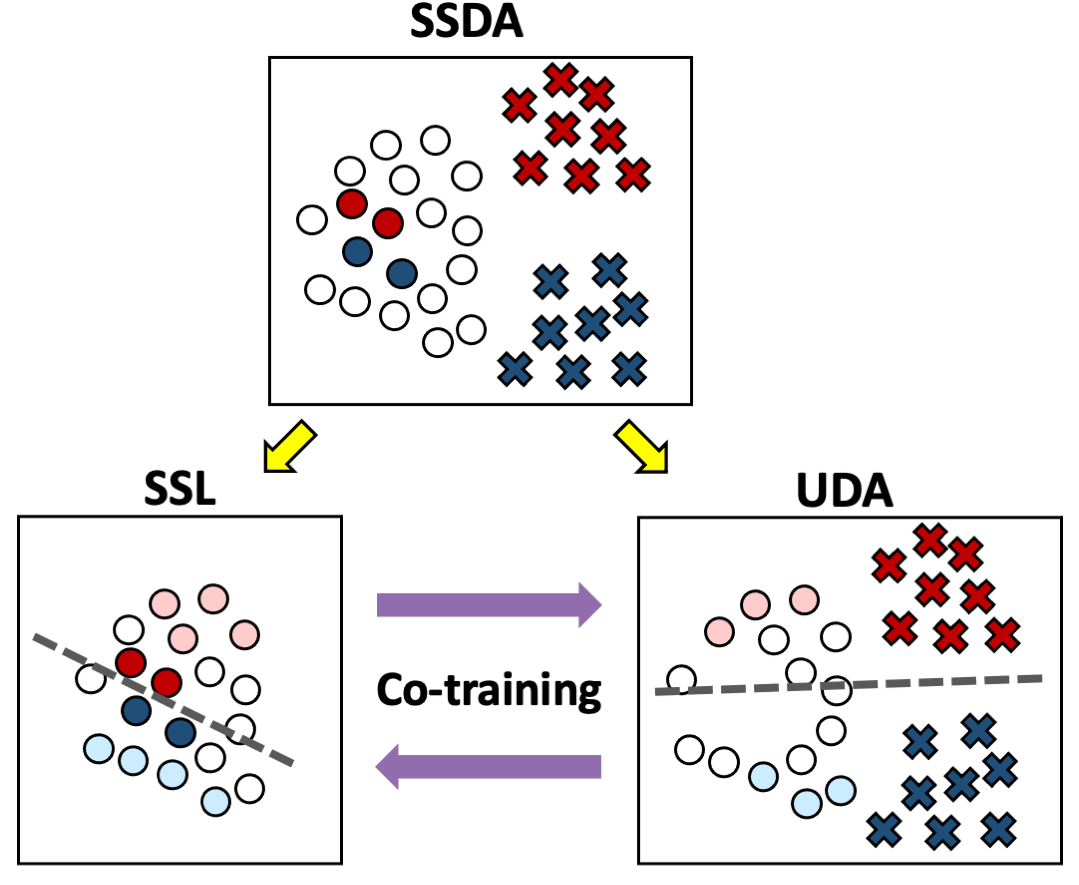

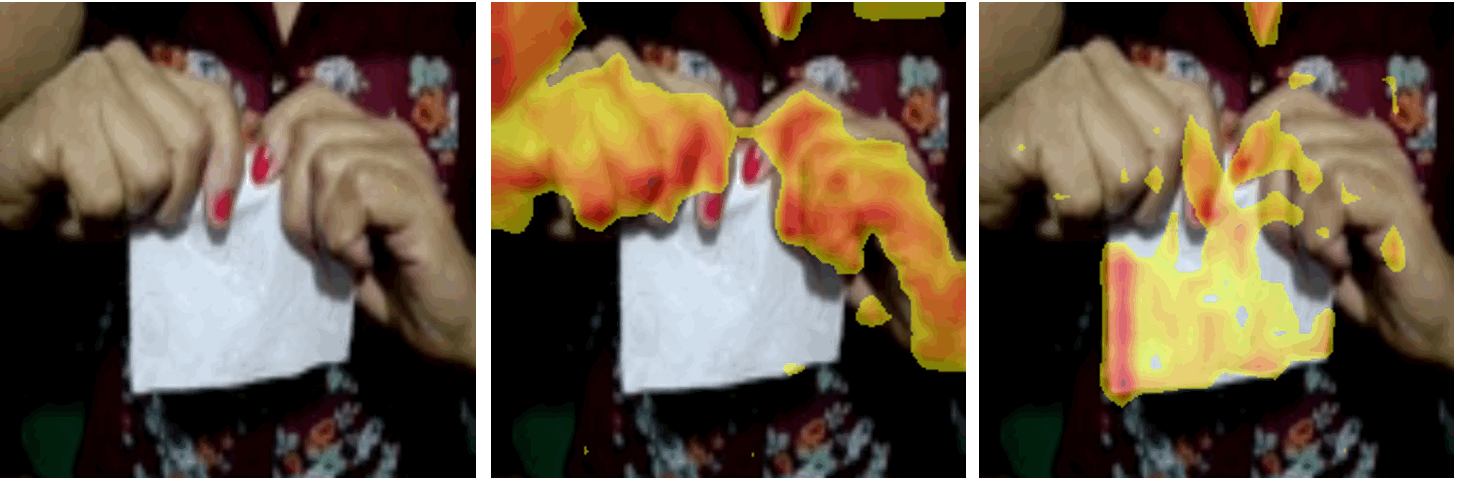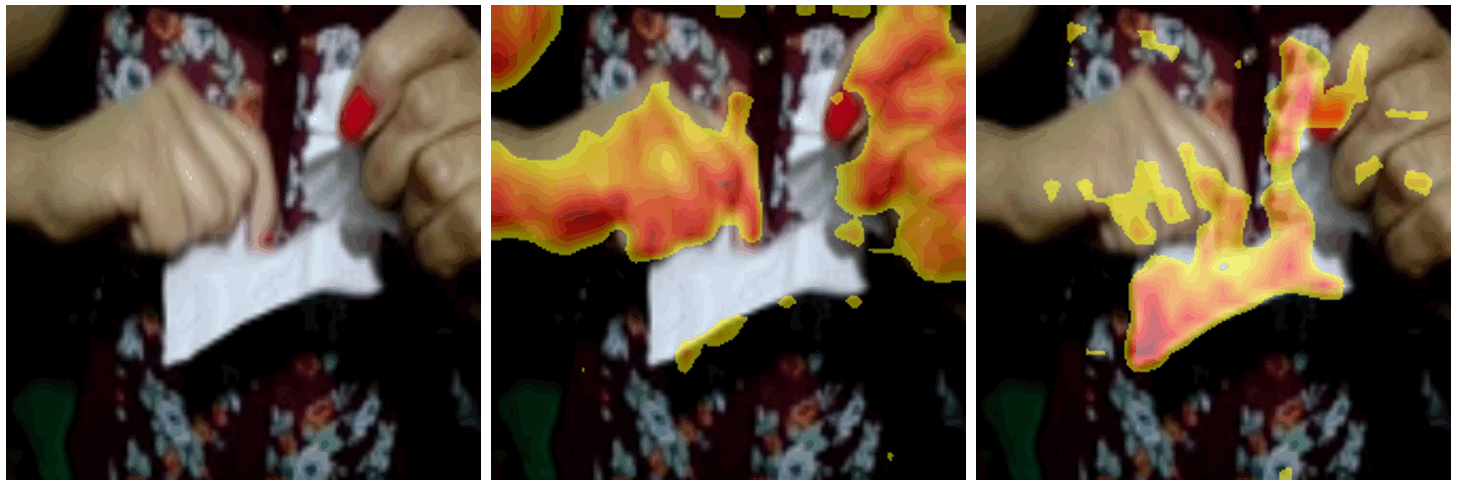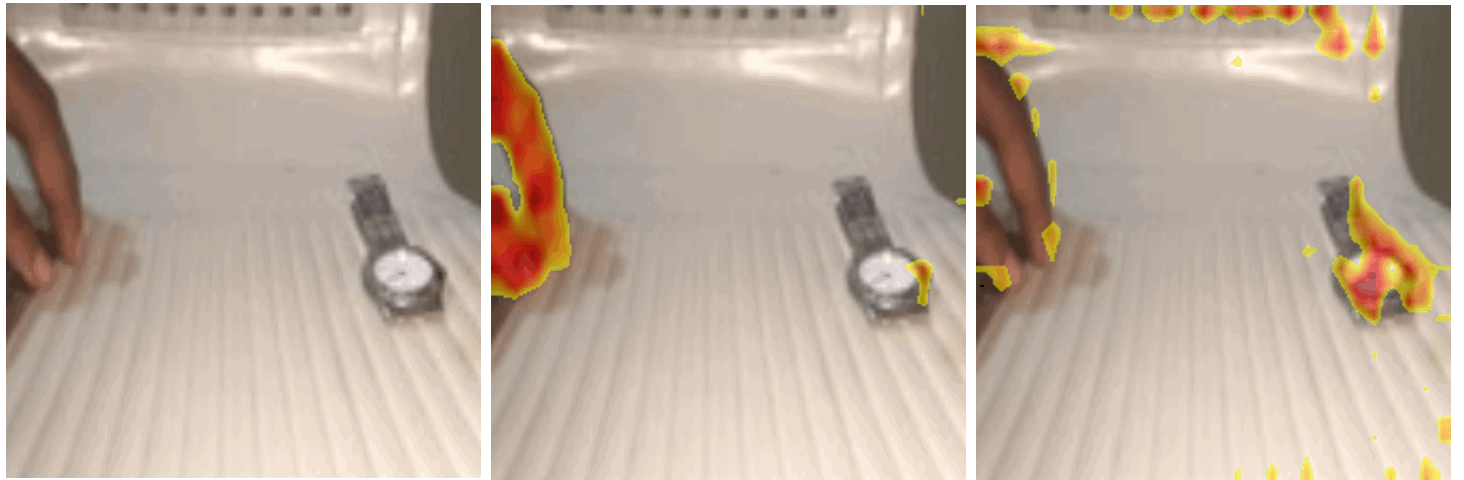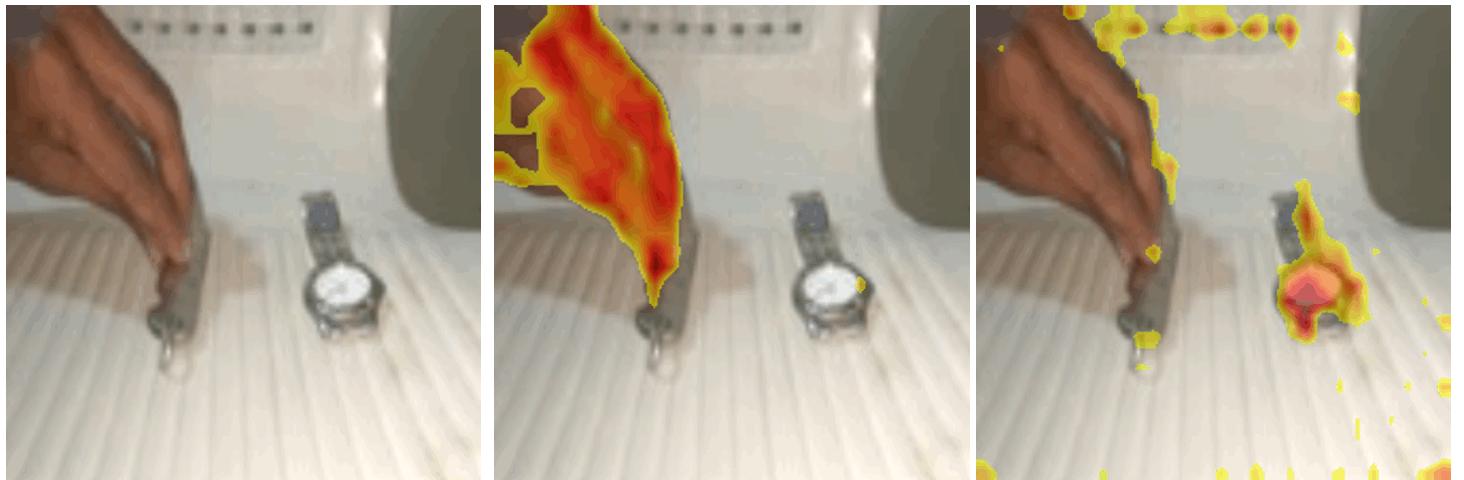
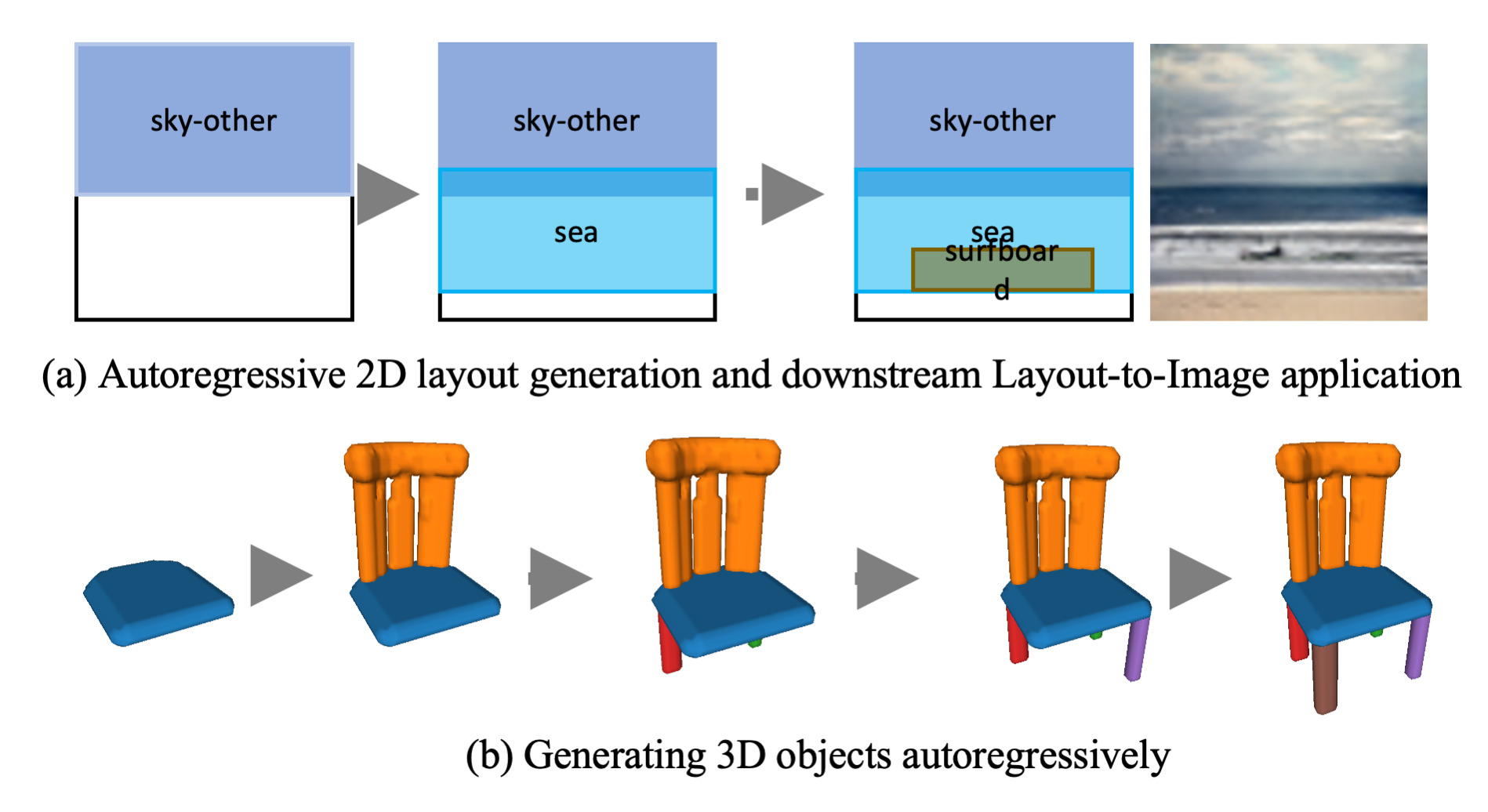
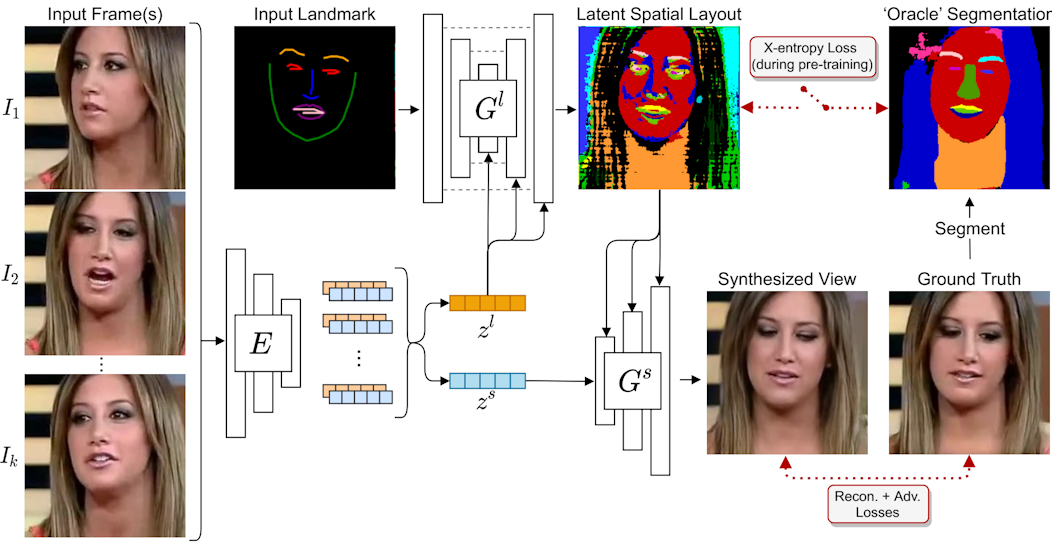
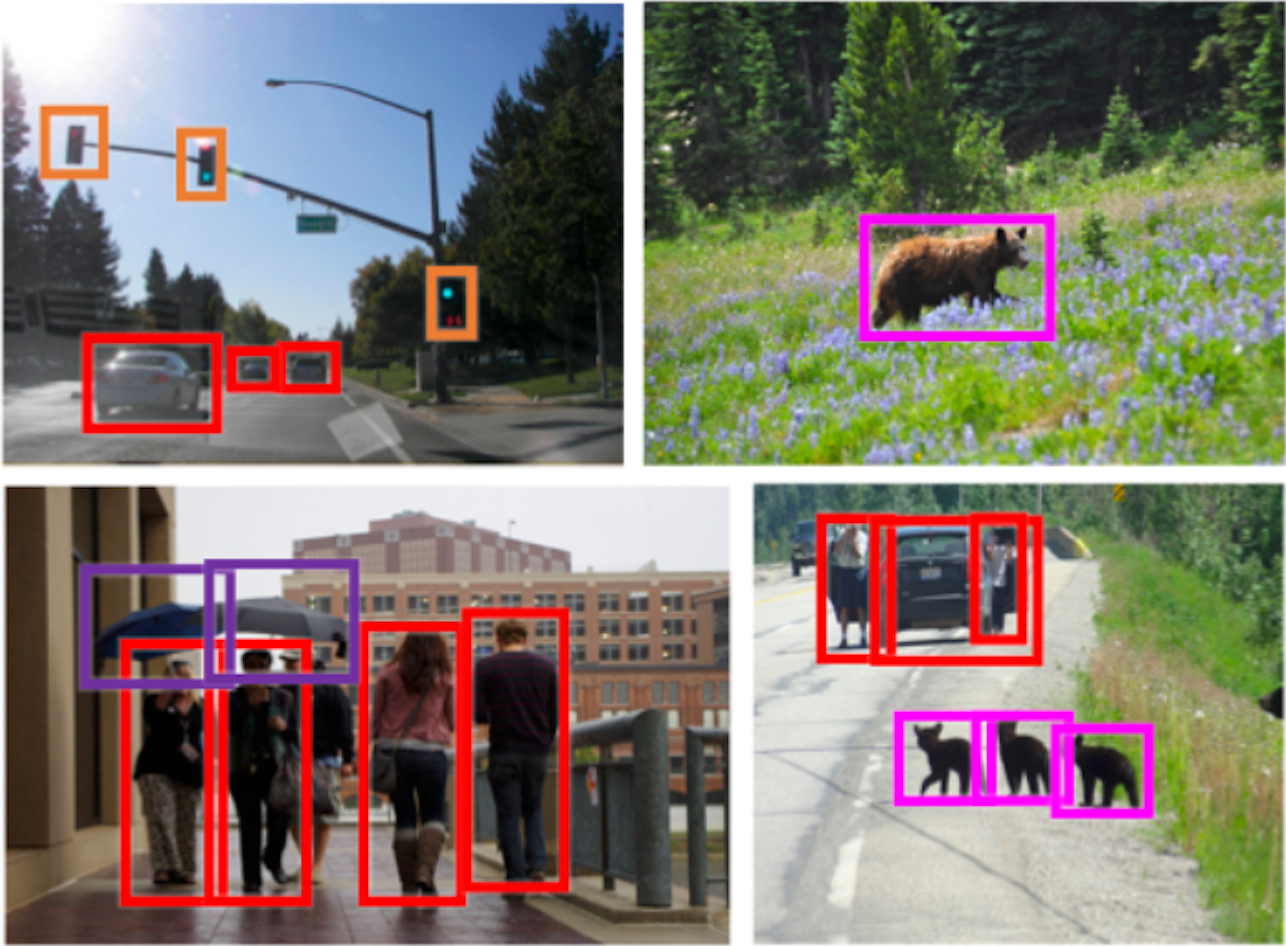
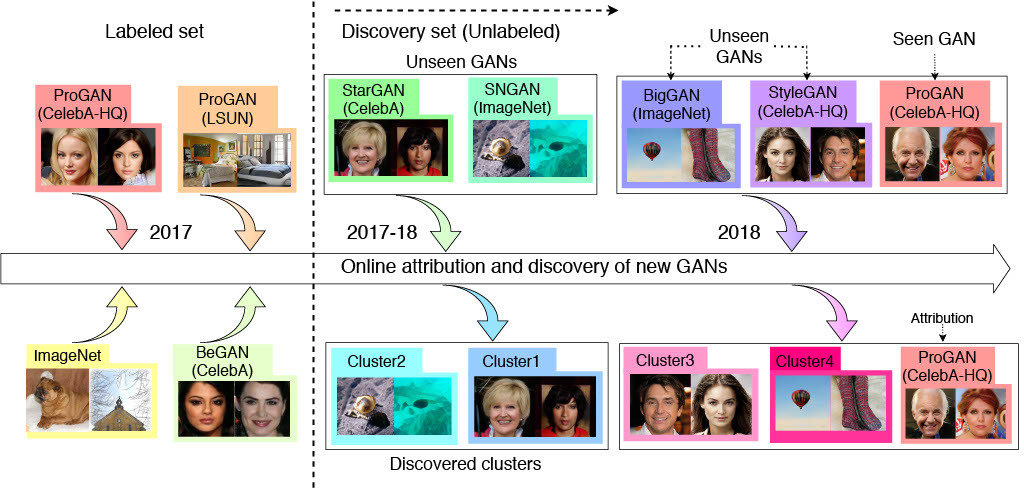







2020





2019
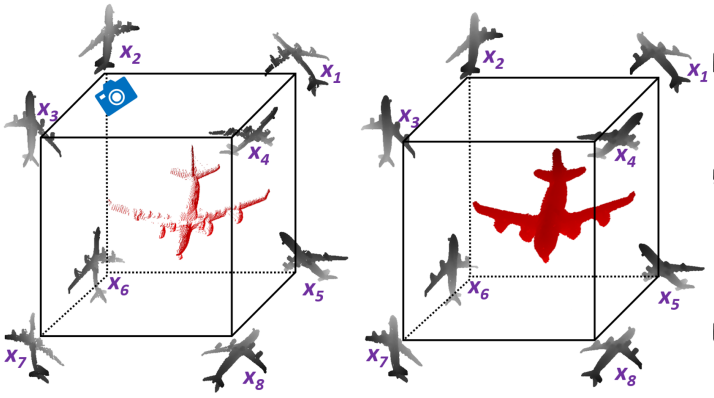
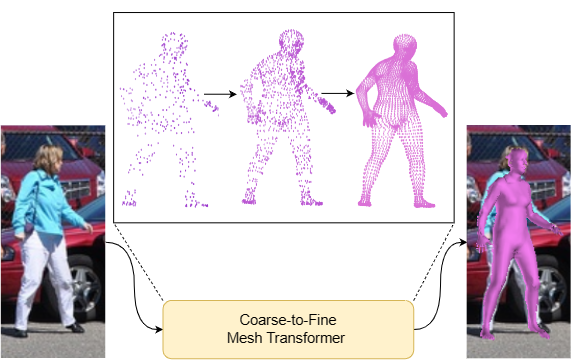
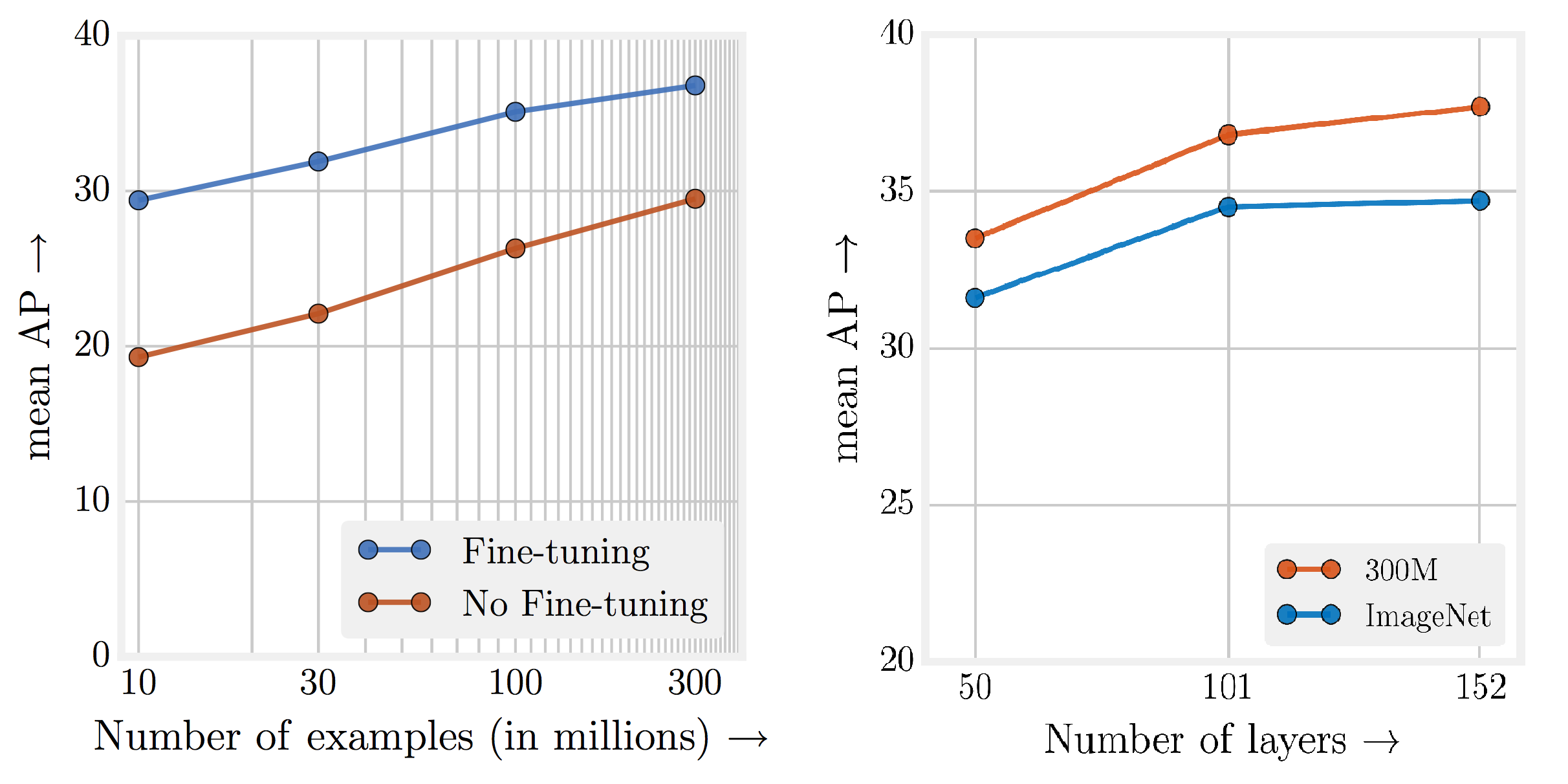
Render4Completion: Synthesizing Multi-view Depth Maps for 3D Shape Completion
GeoMDL Workshop, ICCV 2019
pdf /

2018

2017

2016
2015
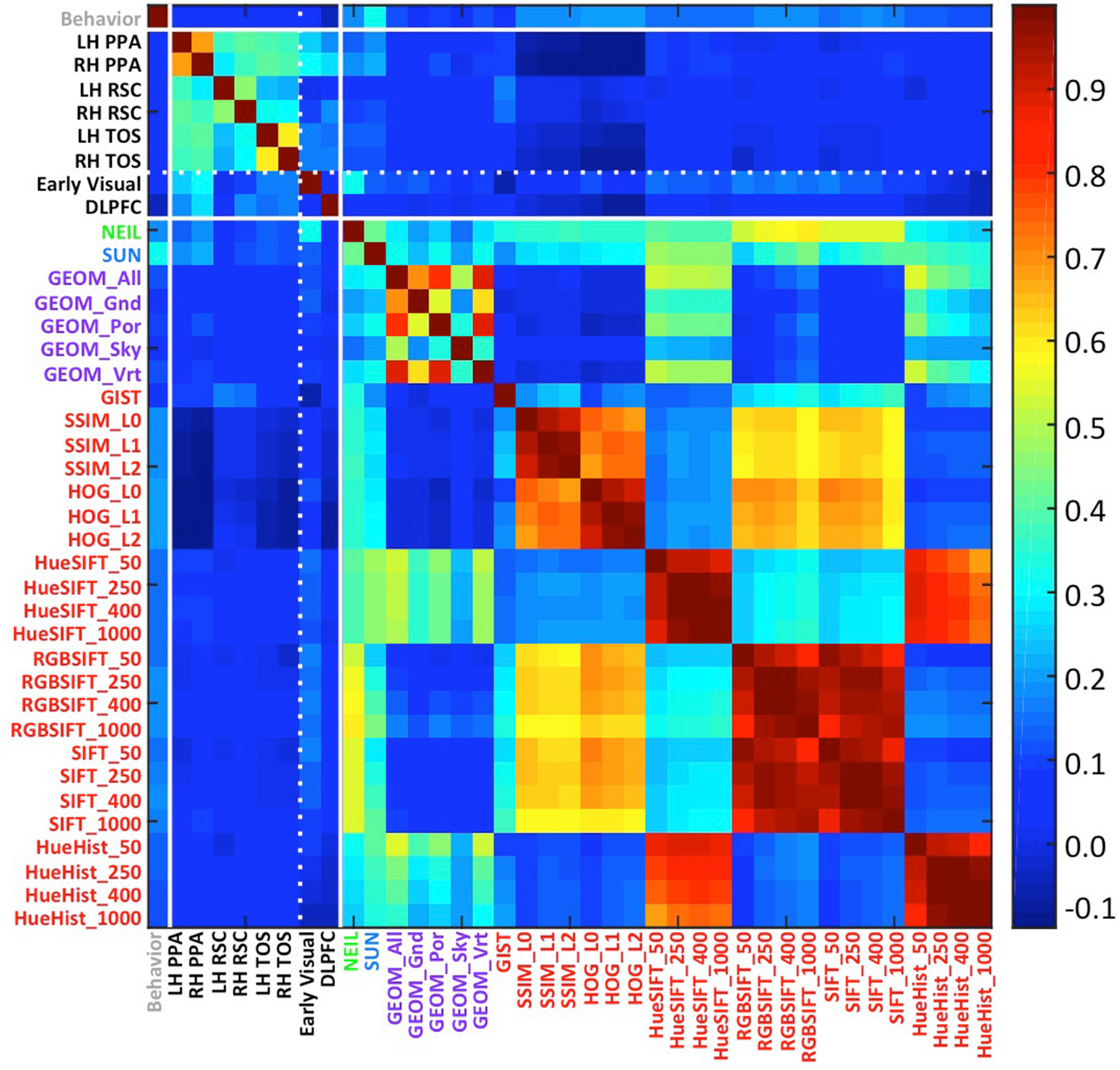
Applying artificial vision models to human scene understanding
Frontiers in Computational Neuroscience 2015
pdf /

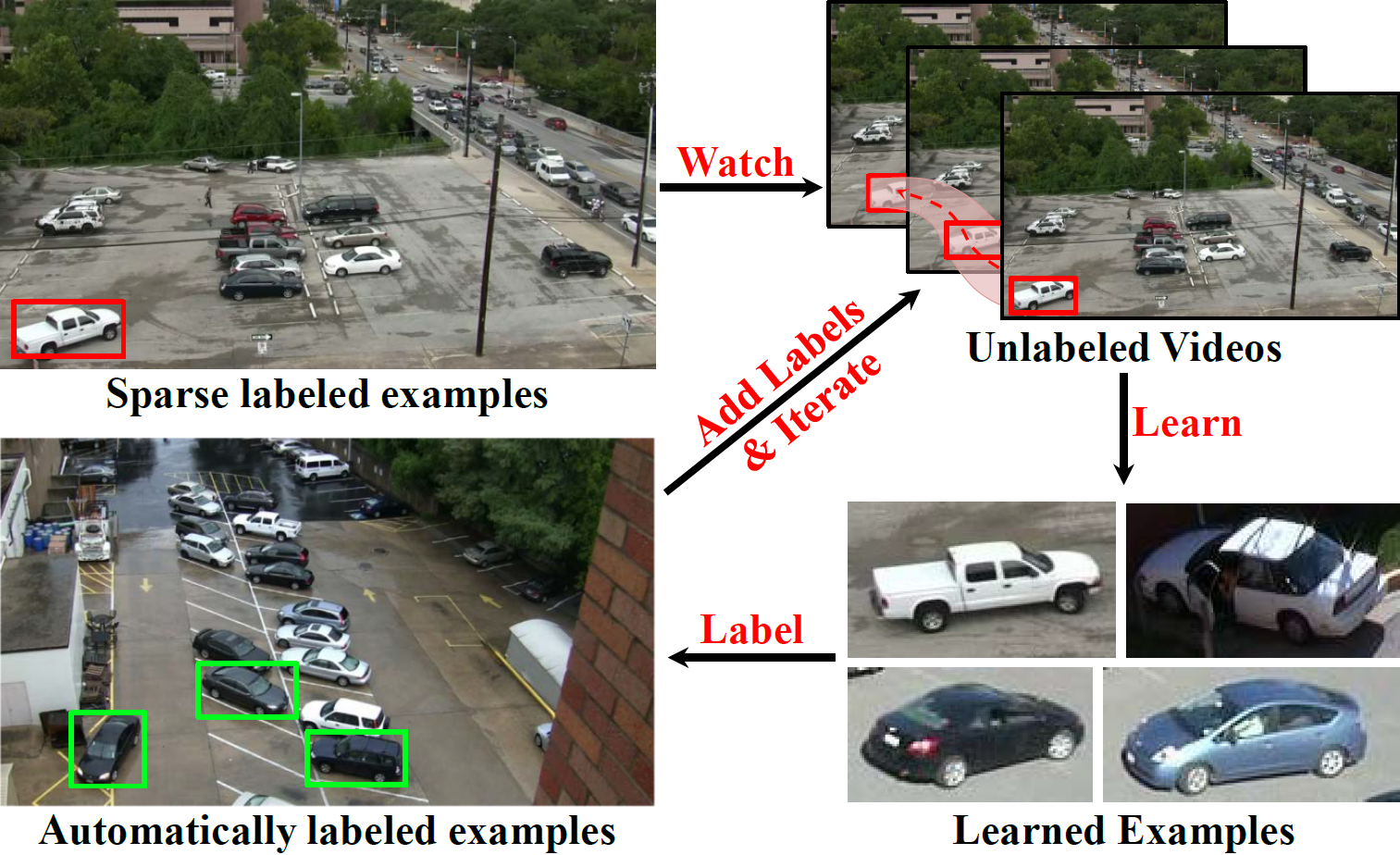
2014

Enriching Visual Knowledge Bases via Object Discovery and Segmentation
CVPR 2014

2013


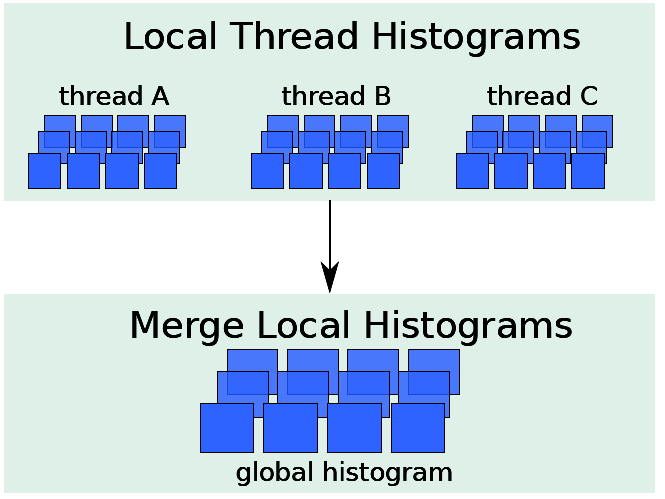
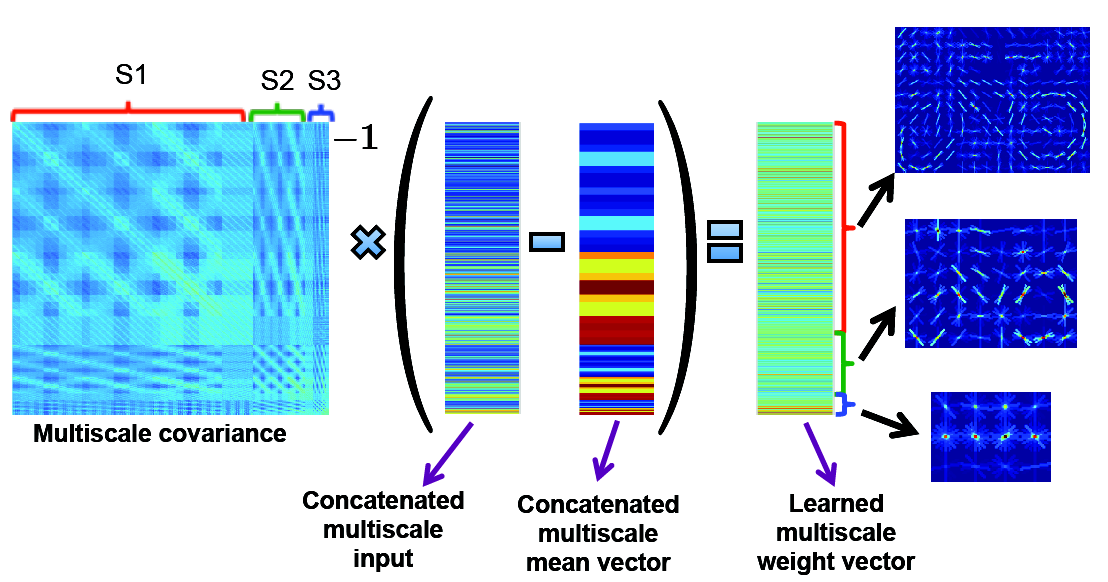
2012
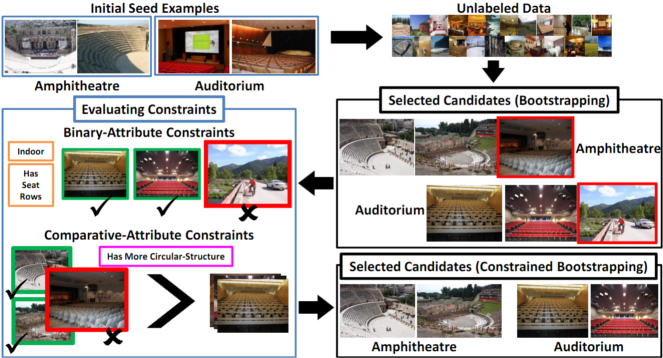


Real-time Household Object Detection from First-person's view using Exemplar-SVMs
Ego-Vision Workshop, CVPR 2012
webpage /
2011

Patents
Action localization in images and videos using relational features
Visual Tracking by Colorization
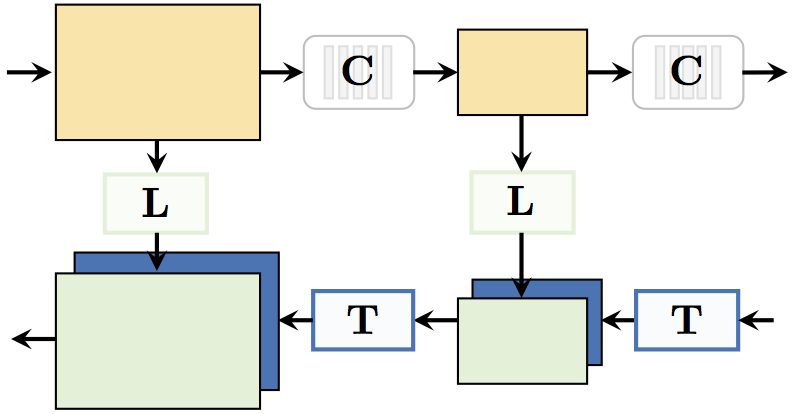
Learning Compressible Features
Compression of Machine-Learned Models via Entropy Penalized Weight Reparameterization
Determining documents that match a query